Einführung
Clean Architecture ist ein Konzept in der Softwareentwicklung, das sich darauf konzentriert, modularen und wartbaren Code zu erstellen. Es ermöglicht Entwicklern, eine Codebasis zu schaffen, die leicht zu verstehen, zu testen und zu erweitern ist. Dabei wird besonders Wert auf die Trennung der zentralen Geschäftslogik der Anwendung von den Details der Infrastruktur gelegt. In diesem Artikel wird die Anwendung von Clean Architecture in Node.js behandelt. Es wird erläutert, wie man sie in seinen Node.js-Projekten mithilfe von Code-Beispielen umsetzt und wie man die Konzepte darauf anwendet.
Das Identifizieren und Lösen von Problemen
Bei der Entwicklung von Node.js-Anwendungen stehen wir oft vor Problemen wie Code-Duplizierung, einer unorganisierten Codebasis und enger Kopplung. Im nächsten Abschnitt werden wir anhand eines einfachen Beispiels für eine Node.js-Anwendung, die Daten aus einer Datenbank abruft und als JSON-Antwort zurückgibt, zeigen, wie diese Probleme gelöst werden können. Clean Architecture bietet Lösungen für diese Probleme, indem sie folgende Prinzipien in den Vordergrund stellt:
Separation of Concerns (SoC)
Dies ist ein grundlegendes Prinzip der Softwareentwicklung, das die Bedeutung der Aufteilung eines Systems in verschiedene Module oder Komponenten betont, die jeweils eine spezifische und unabhängige Verantwortung haben. In Node.js wird SoC oft mit einer modularen Architektur implementiert, bei der jedes Modul für eine einzelne Aufgabe oder Funktionalität verantwortlich ist.
Hier ist ein Beispiel dafür, wie die Trennung der Bereiche auf diesen Code angewendet werden kann:
// index.js - Schlechtes Beispiel !!!
const express = require('express')
const app = express()
const database = require('./database')
app.get('/users', async (req, res) => {
try {
const users = await database.getUsers()
res.json(users)
} catch (error) {
res.status(500).send('Internal Server Error')
}
})
app.listen(3000, () => {
console.log('Server is listening on port 3000')
})In diesem Code haben wir Routings, Datenabrufe und Fehlerbehandlungen in einer einzigen Datei zusammengefasst. Dies kann die Wartbarkeit und Erweiterbarkeit des Codes erschweren, wenn die Anwendung wächst.
Um das Problem zu lösen, können wir das Prinzip der Separation of Concerns auf den Code anwenden:
// index.js
const express = require('express')
const app = express()
const usersRouter = require('./routes/users')
app.use('/users', usersRouter)
app.listen(3000, () => {
console.log('Server is listening on port 3000')
})// routes/users.js
const express = require('express')
const router = express.Router()
const usersController = require('../controllers/users')
router.get('/', usersController.getUsers)
module.exports = router// controllers/users.js
const database = require('../database')
async function getUsers(req, res) {
try {
const users = await database.getUsers()
res.json(users)
} catch (error) {
res.status(500).send('Internal Server Error')
}
}
module.exports = {
getUsers,
}In diesem umstrukturierten Code haben wir die Bereiche Routing, Controller und Datenabruf in drei separate Dateien aufgeteilt. Die Datei index.js ist für die Erstellung der Express-App und die Registrierung der Routen verantwortlich, die Datei routes/users.js ist für die Verarbeitung der Route /users und die Delegierung der Anfrage an den usersController zuständig, und die Datei controllers/users.js ist für den Abruf der Daten aus der Datenbank und die Rückgabe der Antwort an den Client verantwortlich.
Durch die Trennung dieser Bereiche können wir eine bessere Modularität und Wartbarkeit des Codes erreichen. Wenn wir beispielsweise weitere Routen hinzufügen möchten, können wir eine neue Datei im Verzeichnis routes erstellen und sie in der Datei index.js registrieren, ohne den bestehenden Code zu ändern. Wenn wir die Art und Weise, wie Daten aus der Datenbank abgerufen werden, ändern möchten, können wir die Datei database.js modifizieren, ohne den Routen- oder Controller-Code zu ändern.
Dependency Inversion (DI)
In Clean Architecture werden die Abhängigkeiten umgekehrt, was bedeutet, dass die übergeordneten Module von den untergeordneten Modulen abhängen sollten. Dadurch wird sichergestellt, dass die Geschäftslogik nicht mit den Details der Infrastruktur gekoppelt ist.
Hier ist ein Beispiel, wie die Dependency Inversion auf diesen Code angewendet werden kann:
// index.js - Schlechtes Beispiel !!!
const express = require('express')
const app = express()
const usersController = require('./controllers/users')
app.get('/users', async (req, res) => {
try {
const users = await usersController.getUsers()
res.json(users)
} catch (error) {
res.status(500).send('Internal Server Error')
}
})
app.listen(3000, () => {
console.log('Server is listening on port 3000')
})// controllers/users.js
const database = require('../database')
async function getUsers() {
try {
const users = await database.getUsers()
return users
} catch (error) {
throw new Error('Error retrieving users')
}
}
module.exports = {
getUsers,
}In diesem Code hängt die Datei index.js direkt vom usersController-Modul ab, welches wiederum direkt vom database Modul abhängt. Dies verstößt gegen den Grundsatz: Dependency Inversion (Inversion von Abhängigkeiten), da Module auf hoher Ebene nicht von Modulen auf niedriger Ebene abhängen sollten.
Hier ist ein Beispiel, wie die Dependency Inversion auf diesen Code angewendet werden kann:
// index.js
const express = require('express')
const app = express()
const usersController = require('./controllers/users')
const database = require('./database')
app.get('/users', async (req, res) => {
try {
const users = await usersController.getUsers(database)
res.json(users)
} catch (error) {
res.status(500).send('Internal Server Error')
}
})
app.listen(3000, () => {
console.log('Server is listening on port 3000')
})// controllers/users.js
async function getUsers(database) {
try {
const users = await database.getUsers()
return users
} catch (error) {
throw new Error('Error retrieving users')
}
}
module.exports = {
getUsers,
}In diesem überarbeiteten Code haben wir die Dependency Inversion angewendet, indem wir das database – Modul als Parameter an die getUsers-Funktion im usersController-Modul übergeben haben. Auf diese Weise ist das High-Level-Modul index.js nicht direkt von dem Low-Level database – Modul abhängig, sondern beide Module hängen von der Abstraktion der getUsers-Funktion ab.
Durch die Anwendung der Dependency Inversion können wir eine bessere Modularität, Flexibilität und Testbarkeit des Codes erreichen. Wenn wir beispielsweise zu einer anderen Datenbankimplementierung wechseln möchten, können wir einfach ein neues Modul erstellen, das die getUsers-Funktion implementiert, und es als Parameter an die getUsers-Funktion im usersController-Modul übergeben, ohne den vorhandenen Code zu ändern. In ähnlicher Weise können wir das database -Modul zu Unit-Testzwecken einfach nachbilden.
Single Responsibility Principle (SRP)
Jedes Modul oder jede Funktion sollte eine einzige Verantwortung haben. Dies hilft bei der Erstellung einer Codebasis, die leicht zu verstehen und zu pflegen ist.
Hier ist ein Beispiel in Node.js, das das SRP-Prinzip veranschaulicht:
// user.js - Schlechtes Beispiel !!!
class User {
constructor(name, email, password) {
this.name = name;
this.email = email;
this.password = password;
}
saveToDatabase() {
await database.saveUser(user)
.then(() => {
res.status(200).send()
})
.catch(err => {
res.status(400).send('Email Error')
});
}
sendWelcomeEmail() {
await mailService.send(user, 'Welcome')
.then(() => {
res.status(200).send()
})
.catch(err => {
res.status(400).send('Email Error')
});
}
}In diesem Beispiel haben wir eine Benutzerklasse, die zwei Aufgaben hat:
- Speichern von Benutzerdaten in einer Datenbank
- Versenden einer Willkommens-E-Mail an den Benutzer
Dies verstößt gegen das SRP-Prinzip, da die Klasse User mehr als eine Verantwortlichkeit hat und es mehrere Gründe für eine Änderung geben könnte. Wenn wir beispielsweise beschließen, die Art und Weise zu ändern, wie wir Benutzerdaten in einer Datenbank speichern, müssten wir auch die User – Klasse ändern, obwohl dies nichts mit dem Senden einer Begrüßungs-E-Mail zu tun hat.
Um dem SRP-Prinzip zu folgen, können wir diese Verantwortlichkeiten in getrennte Klassen aufteilen:
class User {
constructor(name, email, password) {
this.name = name;
this.email = email;
this.password = password;
}
}
class UserRepository {
saveToDatabase(user) {
await database.saveUser(user)
.then(() => {
res.status(200).send()
})
.catch(err => {
res.status(400).send('Email Error')
});
}
}
class EmailService {
sendWelcomeEmail(user) {
await mailService.send(user, 'Welcome')
.then(() => {
res.status(200).send()
})
.catch(err => {
res.status(400).send('Email Error')
});
}
}
}Jetzt haben wir drei Klassen, von denen jede eine einzige Verantwortung hat:
- Die Klasse
Userist verantwortlich für die Repräsentation eines Benutzers. - Die Klasse
UserRepositoryist verantwortlich für das Speichern von Benutzerdaten in einer Datenbank. - Die Klasse
EmailServiceist verantwortlich für das Versenden einer Willkommens-E-Mail an den Benutzer.
Durch die Trennung der Verantwortlichkeiten haben wir unseren Code modularer und leichter wartbar gemacht. Wenn wir zum Beispiel die Art und Weise ändern müssen, wie wir Benutzerdaten in einer Datenbank speichern, müssen wir nur die UserRepository-Klasse ändern. Die User-Klasse und die EmailService-Klasse bleiben unverändert.
Konzept Design & Schicht Modelle
Clean Architecture in Node.js basiert auf den Prinzipien der Clean Architecture, die von Robert C. Martin (alias Uncle Bob) entwickelt wurden. Sie legt großen Wert auf die Trennung von Verantwortlichkeiten, die Entkopplung von Abhängigkeiten und die Modularität. Das Ziel ist es, eine Codebasis zu schaffen, die einfach zu verstehen, zu testen und zu warten ist.
Die Kernidee hinter Clean Architecture ist die Aufteilung der Anwendung in verschiedene Schichten, wobei jede Schicht eine bestimmte Verantwortung hat. Die Schichten kommunizieren miteinander über klar definierte Schnittstellen. Dies ermöglicht eine einfache Änderung und Überprüfung der Anwendung, ohne dass andere Teile der Codebasis beeinträchtigt werden.
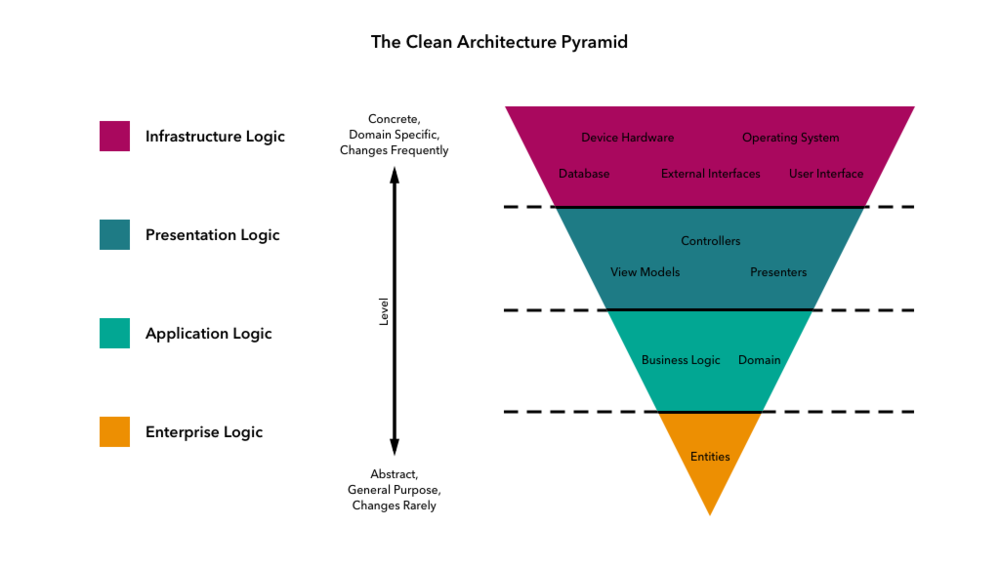
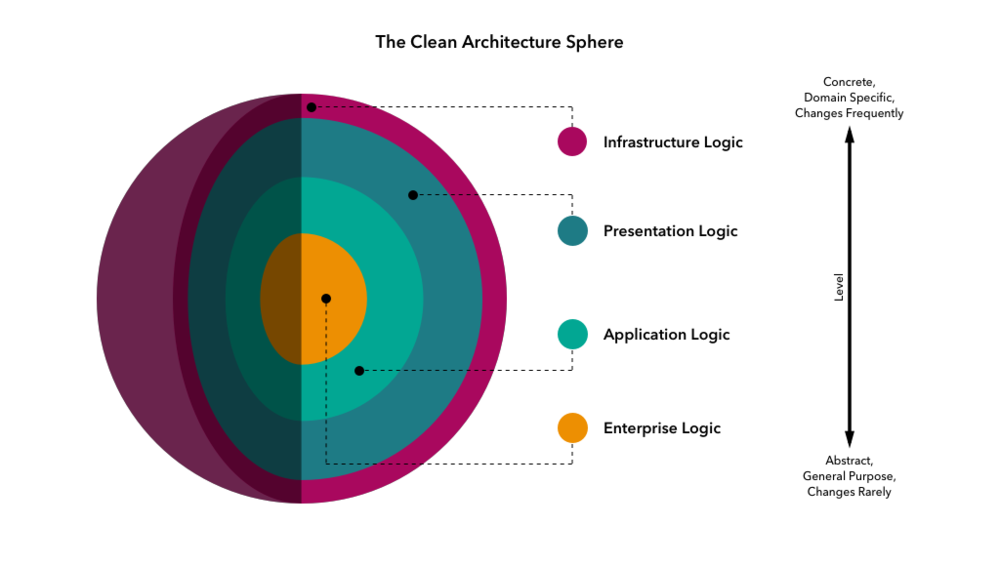
Node.js ist eine beliebte Laufzeitumgebung für die Entwicklung von Webanwendungen. Sie verfügt über ein umfangreiches Ökosystem von Bibliotheken und Frameworks, die zur Implementierung von Clean Architecture verwendet werden können. Hier sind einige der wichtigsten Konzepte der sauberen Architektur in Node.js:
Infrastructure Layer (Infrastruktur-Schicht)
Die Infrastrukturschicht ist in Node.js für die Handhabung externer Abhängigkeiten wie Datenbanken, APIs oder Dateisysteme zuständig. Sie sollte von der Domänenschicht entkoppelt sein, um einfache Tests und Änderungen zu ermöglichen. Die Infrastrukturschicht sollte die Schnittstellen implementieren, die von der Domänenschicht definiert wurden.
In Node.js kann die Infrastrukturschicht mithilfe von Paketen oder Modulen implementiert werden. Ein Beispiel hierfür ist das beliebte Paket Knex.js, das für die Verarbeitung von Datenbankabfragen verwendet werden kann. Die Infrastrukturschicht sollte so konzipiert sein, dass sie steckbar ist und externe Abhängigkeiten leicht ersetzt werden können.
Hier ist ein Beispiel für ein Infrastrukturmodul, das einen Datenbankadapter implementiert:
const knex = require('knex');
class UserDatabase {
constructor(config) {
this.db = knex(config);
}
async getById(id) {
const data = await this.db('users').where({ id }).first();
return data ? User.create(data) : null;
}
async save(user) {
const data = User.toData(user);
const { id } = user;
if (id) {
await this.db('users').where({ id }).update(data);
} else {
const [newId] = await this.db('users').insert(data);
user.id = newId;
}
}
}Dieses Modul bietet Methoden zum Abrufen eines Benutzers nach ID und zum Speichern eines Benutzers in der Datenbank unter Verwendung der Knex.js-Bibliothek.
Presentation Layer (Präsentationsschicht)
Die Präsentationsschicht ist für die Anzeige der Ausgabe der Anwendung für den Benutzer und die Verarbeitung der Benutzereingaben verantwortlich. Sie sollte von der Anwendungsschicht und der Infrastrukturschicht entkoppelt sein. Die Präsentationsschicht kann mithilfe von Web-Frameworks wie Express.js oder Hapi.js implementiert werden.
In Node.js kann die Präsentationsschicht mithilfe von Web-Frameworks oder Modulen implementiert werden. Web-Frameworks bieten eine leistungsstarke und flexible Möglichkeit, die Präsentationsschicht zu implementieren und alle Logik zusammen zu „hosten“.
Hier ist ein Beispiel für ein Präsentationsmodul, das eine REST-API mithilfe des Express.js-Web-Frameworks implementiert:
const express = require('express');
const bodyParser = require('body-parser');
const UserService = require('./services/user-service');
const UserDatabase = require('./infra/user-database');
const app = express();
app.use(bodyParser.json());
const userDatabase = new UserDatabase(config);
const userService = new UserService(userDatabase);
app.get('/users/:id', async (req, res) => {
const { id } = req.params;
try {
const user = await userService.getUserById(id);
res.json(user);
} catch (error) {
res.status(404).json({ error: error.message });
}
});
app.put('/users/:id', async (req, res) => {
const { id } = req.params;
const { userData } = req.body;
try {
let user = await userService.getUserById(id);
user = User.create({ ...user, ...userData });
await userService.saveUser(user);
res.json(user);
} catch (error) {
res.status(404).json({ error: error.message });
}
});Dieses Modul erstellt eine Express.js-Anwendung, richtet den Benutzerdienst und die Datenbank ein und bietet REST-API-Endpunkte zum Abrufen und Aktualisieren von Benutzerdaten.
Application Layer (Anwendungsschicht)
Die Anwendungsschicht ist dafür verantwortlich, die Interaktion zwischen der Domänenschicht und der Infrastrukturschicht zu orchestrieren. Sie enthält die Anwendungsfälle der Anwendung, die die Interaktionen zwischen dem Benutzer und dem System darstellen. Die Anwendungsschicht sollte von der Domänenschicht und der Infrastrukturschicht entkoppelt sein.
In Node.js kann die Anwendungsschicht mithilfe von Klassen oder Modulen implementiert werden. Klassen bieten eine klare Trennung der Zuständigkeiten und Kapselung. Module bieten einen einfacheren Ansatz zur Implementierung der Anwendungsschicht.
Hier ist ein Beispiel für eine Anwendungsklasse, die einen Benutzerdienst repräsentiert:
class UserService {
constructor(userDatabase) {
this.userDatabase = userDatabase;
}
async getUserById(id) {
const user = await this.userDatabase.getById(id);
if (!user) {
throw new Error(`User not found with ID ${id}`);
}
return user;
}
async saveUser(user) {
await this.userDatabase.save(user);
}
}Diese Klasse bietet Methoden zum Abrufen eines Benutzers nach ID und zum Speichern eines Benutzers unter Verwendung des UserDatabase-Infrastrukturmoduls.
Domain (Enterprise) Layer (Domänenschicht – Enterprise)
Die Domänenschicht ist das Herzstück der Anwendung und enthält die Geschäftslogik und Regeln. Sie sollte unabhängig von externen Bibliotheken oder Frameworks sein, um einfache Tests und Änderungen zu ermöglichen. Die Domänenschicht ist der wichtigste Teil der Anwendung, und Änderungen sollten mit großer Sorgfalt vorgenommen werden.
In Node.js kann die Domänenschicht mithilfe von Klassen oder Modulen implementiert werden. Klassen bieten eine klare Trennung von Verantwortlichkeiten, Kapselung und Wiederverwendbarkeit. Module hingegen bieten einen einfacheren Ansatz zur Implementierung der Domänenschicht.
Hier ist ein Beispiel für eine Domänenklasse, die eine Benutzerentität repräsentiert:
class User {
constructor(id, name, email) {
this.id = id;
this.name = name;
this.email = email;
}
changeName(name) {
this.name = name;
}
changeEmail(email) {
this.email = email;
}
static create(data) {
const { id, name, email } = data;
return new User(id, name, email);
}
static toData(user) {
const { id, name, email } = user;
return { id, name, email };
}
}Diese Klasse kapselt die Benutzerdaten und bietet Methoden zum Ändern des Namens und der E-Mail-Adresse des Benutzers.
Verwendung von Paketen von Drittanbietern
Die Verwendung von Drittanbieterpaketen ist eine großartige Möglichkeit, die Sauberkeit Deines Codes zu erhöhen. Es gibt viele verfügbare Pakete, die Dir helfen können, Deine Codebasis zu organisieren und modularer zu gestalten. Zum Beispiel kannst Du ein Paket wie Express.js verwenden, um Routing und Middleware zu handhaben. Du kannst auch ein Paket wie Knex.js verwenden, um Datenbankabfragen zu handhaben. Die Verwendung dieser Pakete kann Dir dabei helfen, Code-Duplizierung zu reduzieren und Deine Codebasis besser zu organisieren.
Hier sind ein paar weitere Beispiele zur Verwendung von Drittanbieterpaketen:
Moment.js
Moment.js ist eine Bibliothek zum Parsen, Bearbeiten und Formatieren von Daten und Zeiten. Durch die Verwendung von Moment.js kannst Du das Schreiben von komplexem Code zur Datumsmanipulation vermeiden und die Wahrscheinlichkeit von Fehlern verringern.
Betrachten wir zum Beispiel den folgenden Code für die Formatierung eines Datums als Zeichenkette:
const date = new Date();
const formattedDate = `${date.getFullYear()}-${date.getMonth() + 1}-${date.getDate()}`;Mit Moment.js können Wir stattdessen den folgenden Code schreiben:
const moment = require('moment');
const date = new Date();
const formattedDate = moment(date).format('YYYY-MM-DD');Dieser Code ist leichter zu lesen und zu pflegen, und die Verwendung der format – Funktion von Moment.js macht deutlich, was der Code erledigen soll.
Winston
Winston ist eine Logging-Bibliothek, die eine Vielzahl von Funktionen zur Protokollierung von Nachrichten bietet. Diese beinhalten verschiedene Protokollierungsstufen, Rotation von Protokolldateien und anpassbare Formatierung. Indem man Winston verwendet, kann man das Schreiben von individuellem Protokollierungscode vermeiden und sicherstellen, dass die Protokolle konsistent und leicht zu lesen sind.
Betrachten Wir zum Beispiel den folgenden Code für die Protokollierung einer Meldung:
console.log(`[${new Date().toISOString()}] INFO: User logged in`);Mit Winston können Wir stattdessen den folgenden Code schreiben:
const winston = require('winston');
const logger = winston.createLogger({
level: 'info',
format: winston.format.combine(
winston.format.timestamp(),
winston.format.printf(info => `[${info.timestamp}] ${info.level}: ${info.message}`)
),
transports: [
new winston.transports.Console(),
new winston.transports.File({ filename: 'app.log' }),
],
});
logger.info('User logged in');Dieser Code ist besser konfigurierbar und leichter zu lesen, und die Verwendung von Winston macht deutlich, was der Code ausführen soll.
Zusammenfassung
Das Konzept der Clean Architecture ist eine mächtige Methode, um modularen und wartbaren Code in Deinen Node.js-Projekten zu erstellen. Wenn Du die Prinzipien der Clean Architecture befolgst, kannst Du eine Codebasis erstellen, die leicht verständlich, testbar und erweiterbar ist. Dabei kannst Du auch auf Drittanbieter-Pakete und verschiedene Ordnerstrukturen zurückgreifen, um die Sauberkeit Deines Codes zu erhöhen. Durch die Implementierung der Clean Architecture in Deinen Node.js-Projekten kannst Du häufige Probleme wie Code-Duplizierung, eine unorganisierte Codebasis und eine enge Kopplung vermeiden.